Climate Futures Toolbox
Making it easier to gain insight from Big climate data
If you sit down at your laptop and try to download climate change data for your local town, watershed, or National Park, you will likely be greeted with a monumental barrier, BIG data.

“Big data” has become a buzzy advertising phrase in recent years, but “Big” was originally intended to describe datasets that could not fit on a single computer and required special strategies to manipulate, download, or analyze. Now that modern society has moved deep into the age of Big data, those constraints of working with Big data have trickled down to all computer users. The massive size and confusing structure of Big data are creating new problems for new populations of people who are trying to use climate data to make their own plans for mitigating the effects of climate change. Earth lab stepped in to help by building a tool that allows users to gain their own insights and make important decisions about their own future, using Big data. Our aim is to take the pain out of Big data.
Climate Futures Toolbox (CFT) is a shining example of the types of tools we build at Earth Lab. It is an open-source software package that bridges the gap between “Big” climate data (e.g. MACAv2Met climate data via a USGS API) and meaningful climate insights. Users no longer need to download the entire climate dataset to their computer and then slog through expansive tables to find the data they want. Instead, users can specify the climate variables and geographic areas they’re interested in and download those data as small, manageable chunks that directly serve the climate questions they are trying to answer.
CFT is a need, not a want. We developed CFT because our partners at the US National Park Service are actively trying to prepare our National Parks for climate change and they need regular, easy access to climate data and climate projections to do that. Before CFT, these devoted researchers would spend 6 days downloading and saving climate projections to a large, on-site hard drive before they could then work with those data to develop scenarios. The cumbersome overhead required to shepherd those data from download though analysis took so long that the team could only finish reports on 2-3 National Parks per year. With more than 400 parks in the National Parks system, it was going to take 200 years to plan the next 50 years of climate change responses. Something needed to be done to speed up that process and CFT was our answer.
CFT was born from the struggles of our National Park Service partners, but it was raised to adulthood by the North Central Climate Adaptation Science Center (NC CASC) and Earth Lab. The NC CASC is a research center dedicated to synthesizing climate data and serving as a climate resource for US Department of Interior entities, like the National Park Service. Members of NC CASC saw these struggles and they started searching for pragmatic solutions. When they saw that Big data were causing such major pain points for the team, NC CASC leveraged their relationship with Earth Lab to develop CFT and remove that pain from Big data.
Let’s walk through a short example to see how easy and pain-free it can be to download and use MACAv2Met climate data via a USGS API.
1) Explore the data library to see what’s possible.
Download and install from CRAN:

Or, install the development version from GitHub:

2) Decide which data to download.
These are the variables and scenarios available from the data cube.

3) Request your data table.

4) Aggregate those data to areas of interest.
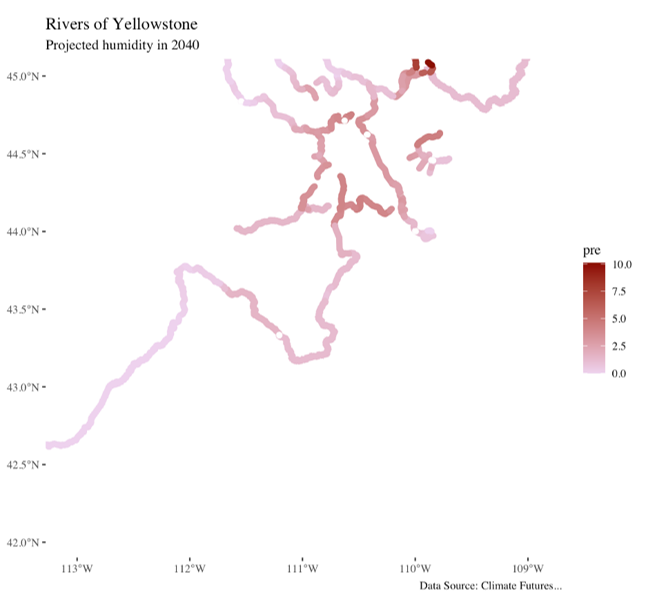
Our partners at the National Park Service use CFT in a slightly more sophisticated way.
They use CFT to download multiple alternative climate scenarios and compare the relative predictions given by those scenarios to try to prepare for the future they see as the most likely. Their great work reminds us that downloading these data is only the first step in linking Big data with decision making. They then take those data and use hypothesis-driven analytical techniques to draw credible inferences from those data.
CRAN Homepage: https://cran.r-project.org/web/packages/cft/index.html
Github repo: https://github.com/earthlab/cft

