Vegetation mortality and burn severity in the 2018 SoCal Woolsey Fire
We examine the relationship between vegetation mortality and burn severity during the Woolsey Fire by using a machine-learning approach to analyze pre- and post-fire satellite imagery.
Project Overview
Over two weeks in November 2018, the Woolsey Fire burned nearly 100,000 acres in the Santa Monica Mountains north of Malibu, California (Fig. 1). Three people were killed in the fire and over 1,600 structures were destroyed. Two other fires that ignited the same day as the Woolsey Fire caused widespread damage throughout California.
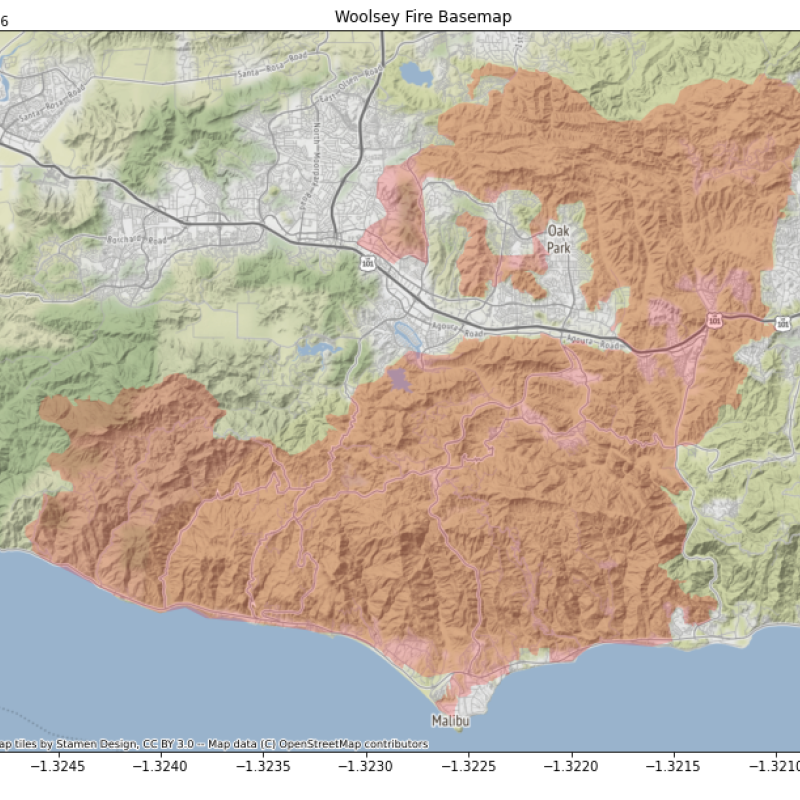
Figure 1. Woolsey Fire burn scar overview map.
Wildfires like the Woolsey Fire pose an increasing threat to life, property and ecosystems in the American West. Larger fires and longer fire seasons stress emergency response personnel and budgets while more people move into the urban-wildland interface where fires are more likely. Understanding the factors that drive wildfires may allow authorities better manage them, mitigating some risks in the fire-prone West.
Drought influences fire severity by drying out soil and killing vegetation that can serve as fuel. The Woolsey Fire was preceded by a four-year drought (2013-2016) that resulted in a significant dieback of grass, shrubs, and trees throughout California. How did that dieback influence the spread and severity of the Woolsey Fire?
In this project, we will examine the relationship between vegetation mortality and burn severity during the Woolsey Fire by using a machine-learning approach to analyze pre- and post-fire satellite imagery. We plan to test the following hypotheses:
- Areas with greater vegetation mortality will show worse burn severity
- Areas with older vegetation mortality will show worse burn severity
Data sources
This study leverages data collected for an earlier survey of the 2013-2016 drought (Table 1). That study's authors used high-resolution data from NASA's AVIRIS sensor to create vegetation community (Fig. 2) and fraction-alive (FAL) maps (Fig. 3) that document the health of the vegetation in the area later burned by the Woolsey Fire. They also compiled 4-km weather data to understand how different communities reacted to the prolonged drought. Using the FAL data, we also calculated fraction-alive difference (dFAL) plots to quantify changes in vegetation mortality during each year of the California drought.
Table 1. Data Sources
| Data Type | Source | Description | Source Spatial Resolution |
|---|---|---|---|
| Vegetation Community | NASA | Classified vegetation communities; derived from AVIRIS sensor data |
15.6 m |
| Relative Fraction Alive (RFAL) | NASA | Proxy for healthy vegetation; time series from 2013-16 |
15.6 m |
| Difference Normalized Burned Ratio (dNBR) | MTBS | Indicator of burn severity; derived from Sentinel-2 data from 2017 and 2018 |
30 m |
| Digital Elevation Model (DEM) | USGS | Elevation data for characterizing terrain; used to create derivatives such as slope and aspect |
1 m |
| Weather | NRCS | Data layers obtained include Days of Precipitation, Vapor Pressure Deficit, Minimum Temperature, Days over 95 Degrees, Cumulative Precipitation. These data represent annual aggregates for the years 2013-2016. |
4 km |

Figure 2. Vegetation Classification Data within the Woolsey Fire burn scar.
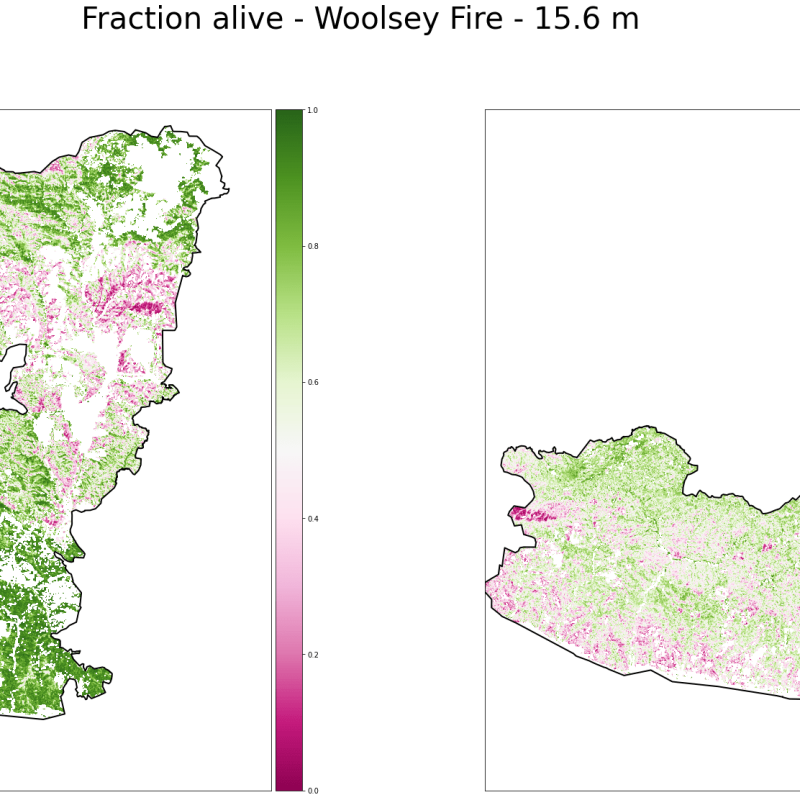
Figure 3. Fraction Alive Rasters, 2013 (left) and 2016 (right). These data are a proxy for the presence of healthy green vegetation.
We are also using burn severity data for the Woolsey Fire from Monitoring Trends in Burn Severity (MTBS), an interagency program that creates normalized, field-validated Normalized Burn Ratio plots for recent wildfires (Fig. 4).
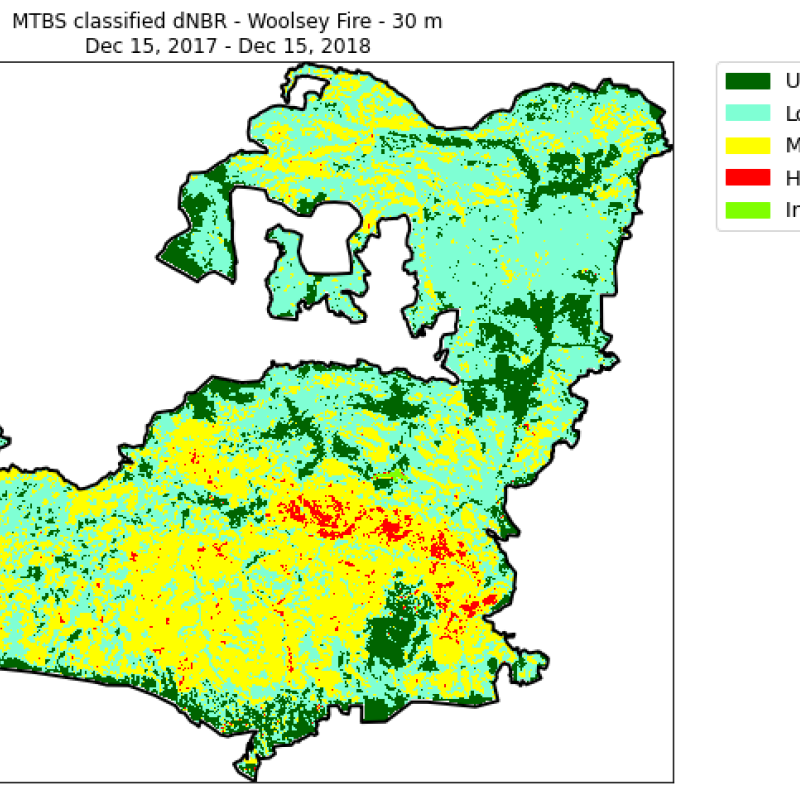
Figure 4. MTBS Difference of Normalized Burn Ratio, 2017-18. These data are indicative of burn severity.
Workflow
We plan to use the random-forest machine-learning algorithm to evaluate how vegetation mortality affects burn severity. As such, we must first select the explanatory and response variables we want to model.In order to characterize the relationships between the available data, we are analyzing pairwise linear regressions.
We plan to evaluate two aspects of the pre- and post-fire system, both of which have obvious response variables:
- Drought-resistance of different vegetation communities (response=FAL or dFAL)
- Burn severity (response=dNBR)
Selecting explanatory variables requires a closer look at the vegetation and climate data. Each data source (described in more detail below) provides data in a different coordinate reference system (CRS), resolution, and extent, so we projected all data to the same CRS, resampled it to the same resolution, and cropped it to the same extent before beginning our analysis. The reprojected data contains roughly 1.6 million pixels inside the Woolsey Fire scar. To reduce computation times, we've filtered the data using two approaches:
- Creating training and validation datasets of a few thousand pixels a piece inside the fire scar. We will ultimately use these subsets to train and validate the random-forest model, but are currently using them to evaluate linear regressions.
- Aggregating high resolution data into 4-km blocks.
Preliminary results
The pixel data, even when reduced to a sample of a few thousand pixels, is very noisy. For analyses of drought resistance, a major source of noise is the low resolution of the climate data. Each 4-km block of climate data corresponds to thousands of points in the higher-resolution datasets, which span a range of vegetation types, slopes, and elevations, producing large spreads of data (Fig. 5). But even the fire data is noisy at the scale of the full dataset or individual vegetation communities. We plan to address this problem, as described below in the Future Work section.
The 4-km aggregate data has been more useful for finding correlations, but so far the only relationships that we've tested are between dNBR and FAL/dFAL. Burn severity correlates positively with (1) vegetation mortality in 2013 and (2) area of vegetation that died between 2013 and 2014.
Future work
We plan to address the noise in the sampled data by looking at specific subsets. So far, we have only looked at individual vegetation communities across the full study area, but we plan to combine community data with climate, elevation and slope data to identify subsets that respond clearly to drought or fire. We also plan to refine the aggregation methods mentioned above and investigate additional variables using the 4-km blocks.
Once we've selected the explanatory variables, we will begin running random-forest models to evaluate how well each explanatory value predicts a response.










